I have been an avid reader of the webcomic xkcd since my days as an undergrad. If you've never heard of it, I would recommend you check it out, some of them are laugh-out-loud funny. There are several comics that stick out as having a simplification theme. I'm going to use this post to look at those comics through the lens of automatic simplification. I'll try to explain what we can do with the current technology and what we just plain can't.
Simple

Particle accelerators are complex beasts. I can empathise with the character who read so much simple Wikipedia that he can only talk in that way now. One of the techniques we use in simplification is language modelling. A mathematical model of sentences is trained which can be used to score new sentences to say how likely they are to have been produced by a language. So for example: "I went to the bank" might recieve a higher score than "I to the banking place did go". As the latter sentence is poorly written. An interesting factor of language models is that the scores they give rely heavily on the sentences which are used to train them. So if you train a model using the text of the English Wikipedia you are likely to get very difficult to understand language. If you train a model using the text of Simple Wikipedia, you are likely to get very simple sounding language, just like the second character in this comic. A great paper which explains this further (without the xkcd references) is Kauchak (2013) (see
the lexical simplification list).
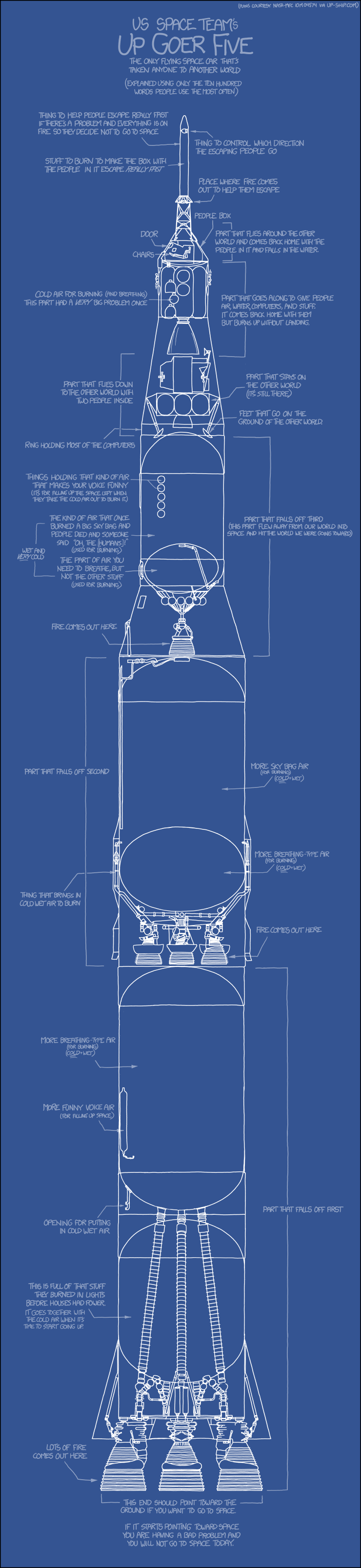
Up Goer Five
This next one is too long to put in this post - but it's worth a read. The full comic is here:
Up Goer Five (Or, right click on the image and open it in a new tab to view).
The comic presents a simplified blueprint of the Saturn V rocket. The translator has been restricted to only the thousand most common words in the English language. There is some question as to where the statistics for the 'thousand most common words' came from. If it were taken from NASA technical rocket manuals then there may have needed to be little change! We'll assume that it was taken from some comprehensive resource. The best way of determining this with currently available resources would be to use the top ranked words in the Google Web1T corpus (Google counted a trillion words and recorded how often each one occurred.)
The style of translation in this comic is phenomenally difficult to achieve, even for humans. You can try it for yourself at
The Up-Goer Five text editor. Most words have been substituted for simpler phrases, or explanations. Some technical terms rely on outside knowledge - which actually has the effect of making the sentence more difficult to understand. For example, one label reads: "This is full of that stuff they burned in lights before houses had power". This is referring to kerosene, which is highly understandable if you know of kerosene but inapproachable if not.
It would be an interesting experiment to determine the lowest number of words required to be able to produce this kind of simplification without having to draw on inferred knowledge (such as the type of fuel lights once burned). My guess is that you would need 10 - 20,000 before this became a reality. It would be difficult to automatically produce text at this level of simplicity. Explaining a concept requires a really deep understanding and background knowledge, which is difficult to emulate with a machine.
Winter
The above comic touches on an excellent point. If the words we use are understandable, does it matter if they're not the correct words? Previously, I have written about
lexical complexity noting that many factors affect how difficult we find a word. The big factor that is played on here is context. For example the term 'handcoats' in the second panel is understandable (as gloves) because we know from the first panel that 'the sky is cold'. Handcoats is a word that you've probably never seen before, and out of context it would be difficult to get the meaning. This highlights the importance of selecting words which
fit the context of a sentence. If the correct context is chosen and a simple word fitting that context is used, then the understandability of a sentence will be dramatically increased.